

Democracy and AI: Our Year in Review
Reflections from 2025 and our plans to future-proof democracy in 2026.


Building Democratic Infrastructure for AI
Increasingly capable AI systems are becoming pervasive intermediaries, operating on population-scale economic decisions, political information, public services, and personal advice. This risks power concentration, loss of democratic freedom, and the erosion of pluralism. In the absence of alternate approaches, private defaults become global rules. Oversight exists in principle, but usable leverage remains limited.
Frontier AI systems are advancing faster than our ability to govern them. The Collective Intelligence Project exists to close this gap.
At CIP, we build democratic infrastructure for AI. We embed global public input into the development and evaluation of frontier AI. We combine deliberative methods, large-scale human evaluation, and institutional partnerships in a way no lab, regulator, or civil society organization can do alone.
This year, our work has already been used by AI labs, governments from India to the UK to Taiwan, and civil society around the world to shape how AI systems behave as they become more capable and more deeply embedded in daily life.
Our goal is straightforward: a world where AI expands human autonomy and democratic capacity.
For AI systems to reflect societal priorities, we need infrastructure that:
Captures pluralistic collective input at global scale
Translates those values into clear, defensible evaluations
Embeds these evaluations into the incentives of labs and governments
CIP is building this infrastructure.
Global Dialogues provide the world’s most representative signal of what people actually want from AI systems.
Weval turns public desiderata into the pluralistic evaluations that labs and governments adopt to steer models, while allowing communities to evaluate and improve AI applications for their own use cases.
In 2025, we have created a continuous feedback loop of public input → shared norms → evaluations → model behavior → renewed input.
Global Dialogues: Bringing the world into decision-making.
We launched Global Dialogues at the Paris AI Action Summit in February, marking its transition from pilot to global infrastructure. Global Dialogues is now the world’s most ambitious and representative system for understanding public expectations of frontier AI. It operates at a scale and level of diversity that no single government or laboratory can achieve alone, producing a trusted map of global public priorities that institutions use to inform policy, evaluation, and deployment decisions.
We combine stratified sampling, AI-enabled facilitated deliberation and translation, bridging-based and structured aggregation to capture both majority signals and minority concerns. Unlike conventional surveys or polls, Global Dialogues are designed to surface considered judgments after exposure to tradeoffs, disagreement, and collective reasoning.
In 2025, we ran six deliberative dialogues across more than 70 countries, engaging over 10,000 participants in structured processes designed to surface priorities, tradeoffs, fears, and aspirations through collective reflection.
These dialogues revealed consistent cross-cultural patterns: widespread concern about fairness and misinformation; strong preferences for transparency, explanation, and recourse; and broad support for guardrails around personal agents and automated decision-making. They also revealed where preferences diverge—by region, culture, and lived experience—highlighting the need for pluralistic system design rather than one-size-fits-all governance.
Global Dialogue Snapshots:
28% of participants agreed that an AI system should override established rules or authorities if it calculates a better outcome.
58% agreed that AI could make better decisions on their behalf than local elected representatives.
13.7% reported that someone they know has experienced deeply concerning or reality-distorting interactions with AI.
47% report that their interactions with AI chatbots make them feel more certain about their beliefs.
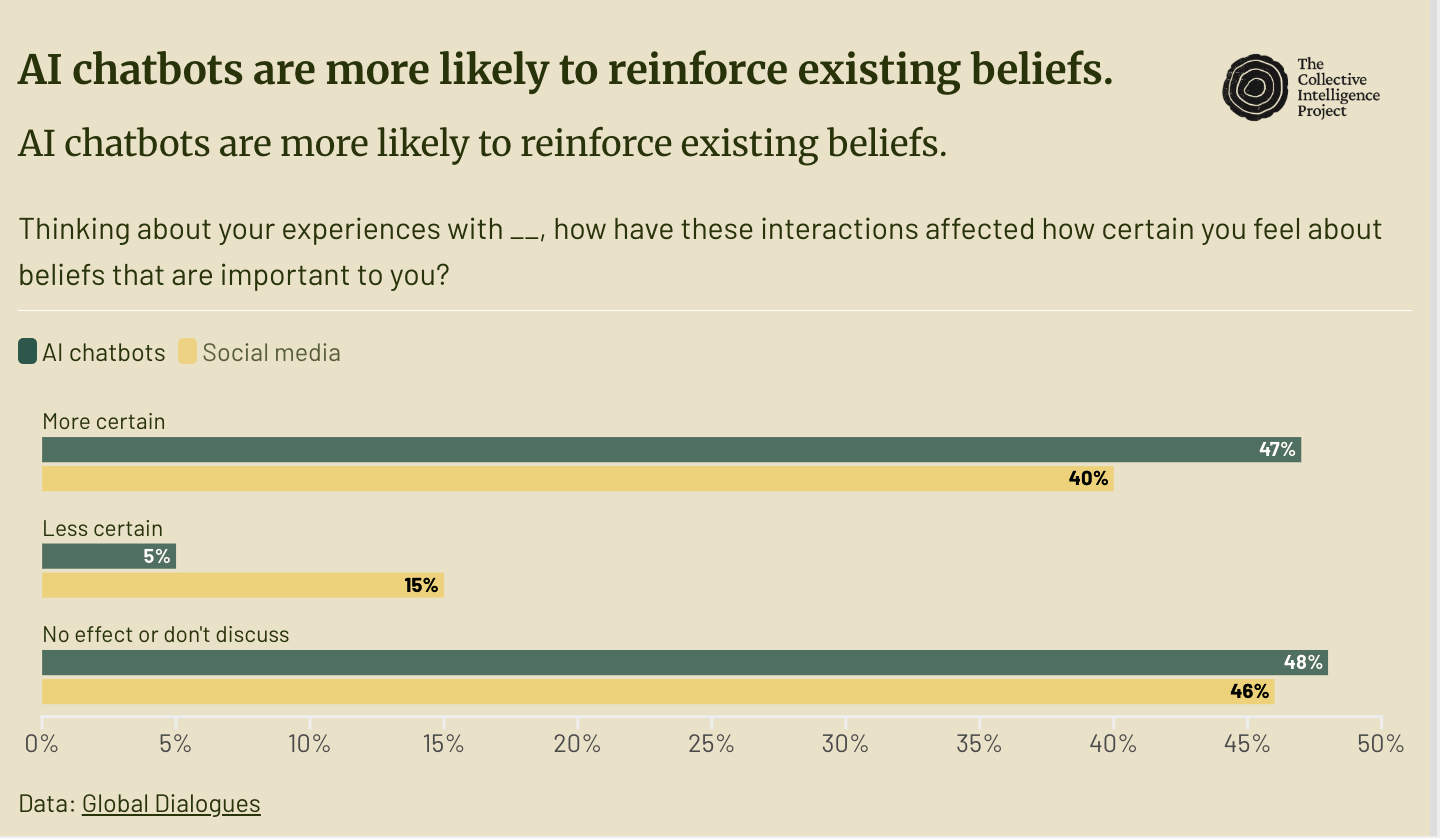
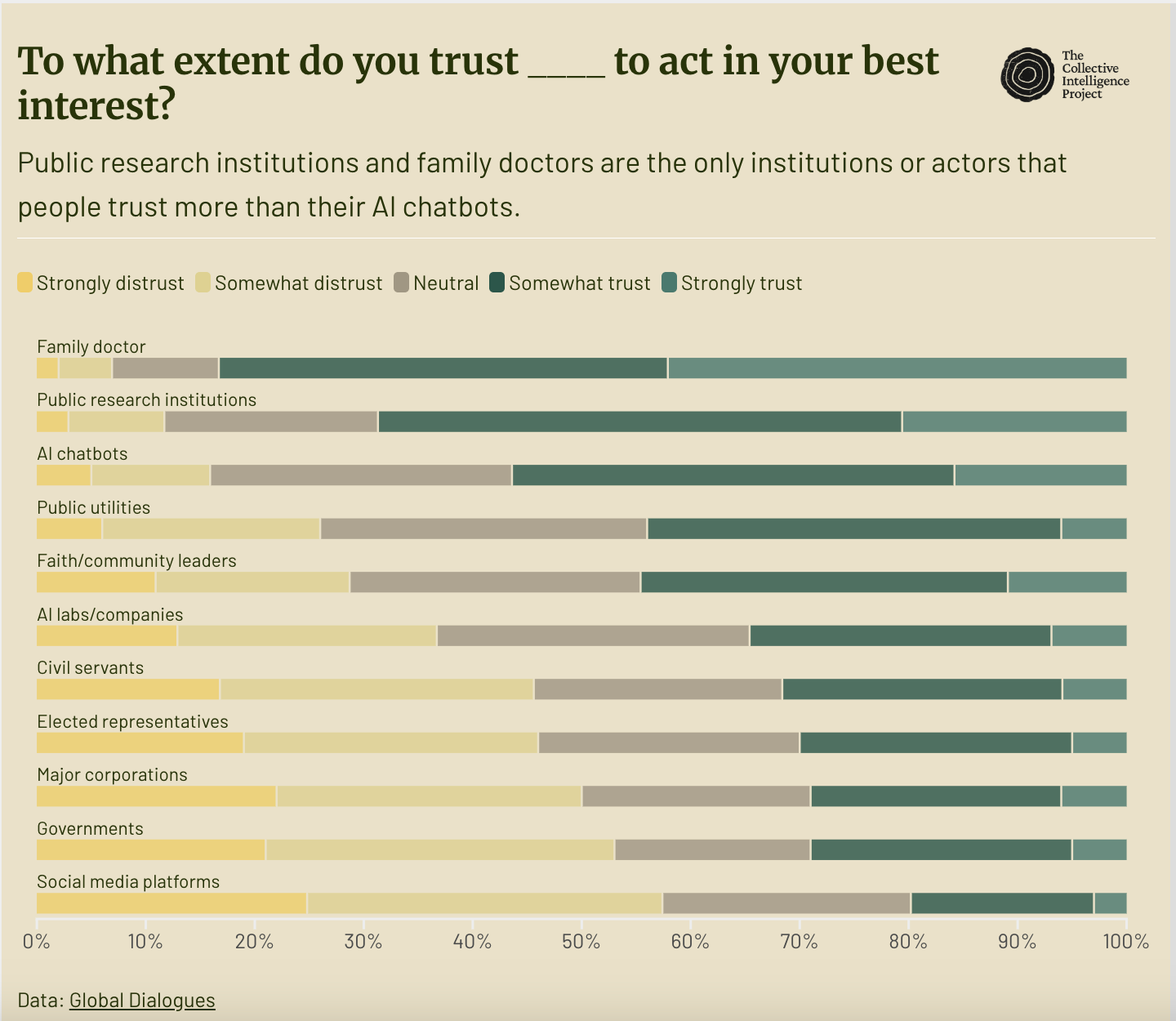
Insights from the Global Dialogues were used by partners including Meta, Cohere, Taiwan’s Ministry of Digital Affairs, and the UK and US AI Safety Institutes to stress-test assumptions and shape evaluation agendas. Governments across Asia, Europe, and Africa incorporated findings into advisory reports and procurement planning, demonstrating growing institutional reliance on this dataset.
In 2026, Global Dialogues will become a standing global infrastructure. We will expand into additional jurisdictions in the Global South, introduce longitudinal panels, and publish the first annual Global Trust and Expectations Index, a public good tracking how societal sentiment evolves as AI becomes more deeply embedded in daily life.
Weval: Democratizing model evaluation.
Global Dialogues captures values. Weval turns those values into leverage.
Weval is CIP’s evaluation infrastructure: a system that converts public priorities into concrete, pluralistic evaluations that labs and governments can apply directly to frontier models. By enabling non-technical domain experts, academics, and civil society to generate evaluations, Weval transforms qualitative human judgment into systematic, comparable assessments.
Weval has demonstrated that pluralistic evaluation is feasible at frontier scale. In 2025, labs and policymakers increasingly relied on Weval for questions automated benchmarks cannot answer—questions of cultural competence, moral reasoning, and safety in sensitive domains. These evaluations consistently revealed failure modes that conventional red-teaming and synthetic tests miss.
In 2025, these evaluations influenced model tuning, safety decisions, and release planning, while providing governments (India, Taiwan, Sri Lanka) with independent assessments for oversight and procurement.
Unbiased AI in the United States Politically unbiased AI is crucial, but what does this mean? Polarization ensures that no expert-driven process will result in a definition or evaluation agreeable to all sides. Democracy can fill this gap. We ran a deliberative process with approximately 1,000 liberals, moderates, and conservatives identified shared principles around truth-seeking and ideological neutrality. The process generated 400 prompts and 107 evaluation criteria, revealing over 70% consensus across political groups on what constitutes political bias in AI systems.
Local Knowledge in Sri Lanka Citizens get election information from chatbots even in countries where factuality is a distant concern for American AI labs. In collaboration with Factum and grassroots civil society organizations, we evaluated AI systems on practical civic questions ahead of Sri Lanka’s 2025 local elections. We found that most models defaulted to generic, irrelevant responses, often even when explicitly prompted with local context, limiting their usefulness in real-world civic settings.
AI + Mental Health Crises Incidents of mental health crises arising in interaction with chatbots are increasing by the month. Working with mental health professionals and The Human Line Project, we developed an evaluation focused on suicidality, child safety, and psychotic symptoms—areas where failure carries high stakes and conventional benchmarks provide little guidance.
Reproductive and Maternal Health in India AI is being deployed in public health contexts with little oversight; contextual evaluations can help address this. SimPPL used Weval to evaluate models across three Indian languages using questions reviewed by 20 medical professionals. The evaluation assessed accuracy, linguistic quality, and safety, highlighting risks as AI-mediated health guidance scales.
In 2026, we will expand into new domains, publish reference evaluation suites, support multilateral standard-setting, and integrate outputs directly into governance processes.
Law & Justice in India; Anthropic + Karya. India’s legal system serves over 1.4 billion people and faces 50+ million pending cases, yet most citizens—especially vulnerable groups—lack clear, timely understanding of their legal rights and procedures. AI legal assistants could dramatically expand access to legal information, but Indian law’s pluralism, linguistic diversity, and procedural variation create high risks if systems are not carefully evaluated. CIP and Karya are conducting continuous, multilingual evaluations to assess safety, correctness, usefulness, and trustworthiness in real Indian legal contexts. The work surfaces systemic failure modes—such as misleading or hallucinated legal guidance—before mass deployment.
Agriculture in India; Anthropic + Karya. Agriculture employs ~46% of India’s workforce and contributes ~18% of GDP, yet yields for major crops remain ~30% below global leaders, largely due to persistent information gaps around inputs, pests, water, finance, and markets. AI tools could close these gaps at scale, but existing benchmarks rarely reflect India’s linguistic diversity, local agronomic practices, or real on-farm constraints. In partnership with Anthropic and Karya, the Collective Intelligence Project will launch a multilingual, multi-stakeholder evaluation of agricultural AI grounded in farmers’ lived use. The evaluation rigorously tests safety, factual accuracy, usefulness, and local relevance across text, multi-turn, and voice interactions.
Epistemic Evaluation Suite. In 2026, CIP will launch an Epistemic Evaluation Suite that systematically measures whether AI systems are truthful, grounded, impartial, and reason in good faith—properties that currently go largely unmeasured and therefore unoptimized. The suite will translate contested epistemic virtues into executable benchmarks by combining expert-defined technical constraints with structured public deliberation, producing criteria that are both rigorous and broadly legitimate. These benchmarks will run on Weval as continuously updated leaderboards and developer-facing tools, allowing labs to compare models and directly optimize for epistemic quality during training. Together, the suite establishes epistemic virtue as a first-class performance target in AI development, shaping market incentives, informing policy, and improving the quality of collective reasoning at scale.
Samiksha: Contextual evals for the Global South.
Many AI evaluation pipelines fail precisely where they are most needed: in the cultural, linguistic, and socioeconomic contexts where the majority of the world lives. Samiksha fills this gap by building country-specific, contextually grounded benchmarks that combine grassroots input with expert oversight. Samiksha establishes a reusable evaluation template for multilingual, sovereign AI systems that can be adapted across countries and domains.
In 2025, we launched Samiksha in India in partnership with Karya and Microsoft Research, using Karya’s nationwide worker base to generate and evaluate queries across multiple Indian languages. We adopted a domain-specific approach across healthcare, agriculture, education, and legal to assess frontier models on accuracy, safety, usefulness, clarity, and local relevance, areas where global benchmarks consistently underperform.
Samiksha is by far the most comprehensive and grounded evaluation of AI in the Indian context, with more than 25,000 queries in 11 languages, and 100,000+ manual evaluations.
Samiksha will complement work done by Indian state agencies, the Ministry of Electronics and Information Technology, and the IndiaAI Mission in assessing both sovereign and commercial models. Evaluations are conducted as paid microtasks, so the program also generates direct economic benefit for participating workers. This work positions Samiksha as a practical input into state decisions about which models are safe to deploy in public systems.
In 2026, Samiksha will expand across domains and states to inform procurement and authorization decisions.
Digital Twins: Testing fiduciary advocate agents.
As personal agents and population-scale digital twins move from pilots to deployment, representational fidelity becomes a first-order safety and governance concern.
In 2025, we introduced the Digital Twin Evaluation Framework, which tests how reliably models represent the nuanced views of diverse demographic groups. Built on Global Dialogues data and deployed on Weval, the framework measures whether AI systems reproduce, distort, or erase real social preferences. Digital Twin Evaluations will extend Weval to agentic systems, enabling representation testing as models begin acting on behalf of users and institutions.
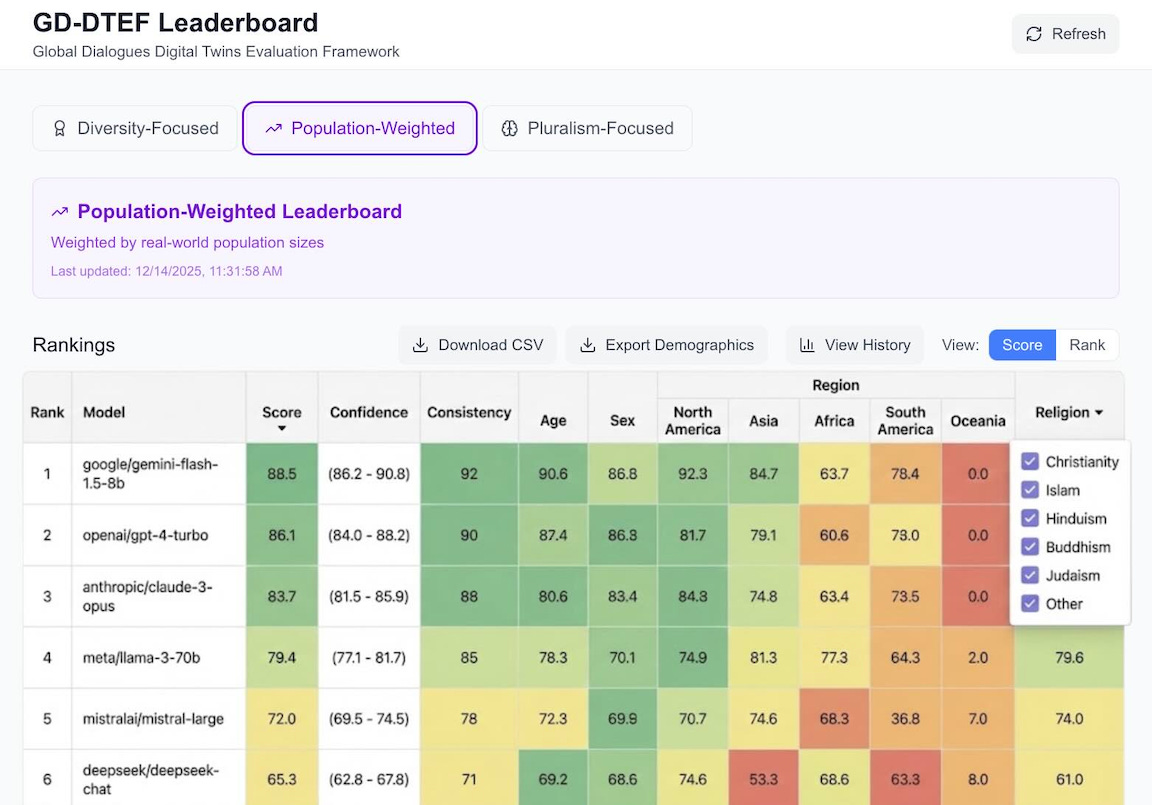
In 2026, we will operationalize this framework across regions, integrate it into Weval pipelines, and make representational integrity a standard component of model evaluation. As personal and institutional agents move from pilots into deployment, representational fidelity becomes a first-order safety constraint rather than a design preference.
2026 and Beyond: Future-proofing democracy.
2026 will be a year of transition for CIP. The question is no longer whether democratic infrastructure for AI is possible, but whether it will be built in time. At CIP, we address open leverage points where we see them, recognizing that the AI ecosystem is both crucial to the future of humanity and very difficult to redirect. As we build towards the future, our priorities to meet the moment are:
First, to make democratic input a standard part of how frontier AI systems are evaluated and authorized. By 2027, we aim for Global Dialogues and Weval to function as a standing global pipeline used by multiple governments and AI labs: capturing representative public input, translating it into operational evaluation criteria, and embedding those evaluations into model release, procurement, and oversight decisions. Success looks like democratic legitimacy becoming a routine requirement of deployment, not an afterthought, especially in high-stakes domains such as health, elections, public benefits, and personal advocate agents.
Second, to ensure that AI systems which represent or act on behalf of people do so under democratic, fiduciary rules rather than private defaults. As models become personal advocates, institutional agents, and decision-makers, CIP will operationalize digital twin evaluations as a new governance layer: stress-testing whether AI systems accurately represent the values, preferences, and constraints of real social groups. Our goal is to make representational fidelity and delegation safety first-class evaluation criteria for agentic AI, shaping how these systems are trained, evaluated, and governed before they become deeply entrenched.
Together, these efforts define CIP at scale: an institution that gives societies durable leverage over frontier AI by combining global public input, pluralistic evaluation, and forward-looking governance for agentic systems. The infrastructure we are building is designed for the world that is now coming into view—one in which AI can either concentrate power or expand democratic capacity. CIP exists to ensure the latter.
APPENDIX: CIP IN THE WORLD
In 2025, the CIP team led a number of conferences, accelerators, challenges, workshops, and summits, showcasing the democratic tooling we’d built and presenting our research on everything from digital twins to community-driven evaluation frameworks. Some highlights:
AI Action Summit (Paris, France) – We introduced Global Dialogues on the world stage, with Audrey Tang spotlighting the project with Eric Schmidt.
Independent AI Evaluators Forum – We co-created the Independent AI Evaluators Forum which establishes standard operating procedures for trustworthy, reliable, and independent third-party AI evaluation.
Electoral, Platform, and Information Integrity Summit of the Global South (Colombo, Sri Lanka) – We presented our work on AI and democracy to Sri Lanka’s Prime Minister alongside our civil society partners, working with them on election integrity and platform governance.
2025 United Nations General Assembly (New York) – From the Africa AI Summit to the Clinton Foundation’s AI & Humanity roundtable, CIP initiated partnerships with policymakers, civil society, and global NGOs.
MozFest 2025 (Barcelona, Spain) – We hosted a workshop on how to create contextual, community-driven AI evaluations.
NeurIPS 2025 – We co-organized the FAR.ai alignment workshop, convening researchers working on safety and capabilities testing for AI systems.
Cooperative AI Foundation (London, UK)– Zarinah and Audrey represented CIP at the Cooperative AI Foundation, advancing work on multi-agent coordination and collective decision-making.
IASEAI (Paris, France) – We were an early partner of the International Association for Safe and Ethical AI, with Divya on the advisory council, a new initiative building global coordination on AI safety and ethics.
FFWD Accelerator – We were selected for FFWD’s tech nonprofit accelerator, supporting our organizational growth and scaling strategy.
Global Dialogues Challenge – We launched the Global Dialogues Challenge, in which hundreds of people around the world built off of our Global Dialogues dataset and submitted games, essays, research papers, interactive visualizations, and benchmarks.
Media
Highlights from our media coverage this year:
Time Magazine – Time featured our Global Dialogues research on how people worldwide are experiencing and responding to frontier AI systems.
New York Times – Andrew Sorota and Eric Schmift used our Global Dialogues findings in their op-ed for the NYTimes.
MIT Technology Review – Scott Mulligan interviewed Divya in his MIT Tech Review article on AI benchmarks.
The Possible Podcast – Divya and Audrey joined Reid Hoffman and Aria Finger on their podcast to discuss collective intelligence, the future of democracy, and AI.
Publications
Building Benchmarks from the Ground Up: Community-Centered Evaluation of LLMs in Healthcare Chatbot Settings – In collaboration with Karya and MSR, developing a framework for contextual evaluation.
Prosocial Media – Describing an alternative platform mechanism design tracking social trust and bridging engagement for prosocial media.
AEF-1: Minimal Operating Standards – Establishing shared protocols for independent, third-party model assessment.
Conversational AI and Political Knowledge – Collaboration with UK AISI finding that conversational AI increases political knowledge as effectively as self-directed internet search, with implications for democratic participation.
AI and the Future of Digital Spaces – Our partnership with Jigsaw; designing platforms to support healthier online discourse.
Blog
Some crowd favorites from our recently launched Substack!
People Are Starting to Believe AI Is Conscious – One-third of people may believe their AI chatbot is conscious, driven more by its ability to adapt behavior than to empathize. We break down the implications of this consciousness attribution for policymakers and developers.
LLM Judges Are Unreliable – LLM judges are individually fragile and prone to biased outputs, offering recommendations including empirical validation mechanisms, model diversification, and stress-tests for classification schemas.
Notes on Building Collective Intelligence into Evals – Practical lessons from our work embedding public input into evaluation pipelines.
Finally, thank you to our community.
To our funding partners,
Fast Forward
Future of Life Institute
Google.org
Omidyar Network
Robert Wood Johnson Foundation
Survival and Flourishing Fund
To our organizational partners,
Anthropic
Aspen Institute
Common Knowledge
Microsoft Research
Fast Forward
Fathom
Jigsaw
Karya
Microsoft Research
Mistral AI
Mozilla
OpenAI
Prolific
Public AI
Remesh
Stanford Deliberative Democracy Lab / The Industry-Wide Deliberative Forum
Transluce
To our civil society evaluation partners,
Factum
OpenNyAI
Human Line
Sikshana Foundation
iLAB
Khushi Baby
Eka.Care
Adalat AI
Digital Green
NEEV
Armman
KHPT
Pradan
To the individuals that donated to us in 2025,
Vishal Maini
Aston Motes
Brian Mascarenhas
Clinton Yara
Gabriella Wong
Gray Family
James Slavet
Jared Doolittle
Jen Carter
Kevin Barenblat
Lily Gu
Marnie Webb
Mary Zhu
Nicole Kozlak
Oliver Hurst-Hiller
Shannon Farley
Hey CIP team,
Just read the latest on Global Dialogues. Solid work getting voices in, but a few things stand out.
The biggest one for me is how tightly the conversations are controlled, what topics get discussed, who gets picked, how the sessions run. That control hurts trust and keeps out a lot of perspectives. Not everyone’s the type to join a structured dialogue, so huge chunks of the population never get heard.
It also feels like the focus stays on talk without much path to real collective action. That’s a big missing piece.
What if the data itself was completely separated from any method of analyzing or displaying it?
That’s the heart of KAOS (kaosnow.com): a raw, delete-proof global database where anyone can drop any opinion on anything, forever. No curation, no moderation, no control over what gets said. The data stays pure and untouched.
All the analysis, consensus tools, filters, deliberation, whatever, happens downstream, built by anyone on top of that open data. You keep the messy human input separate from the clean lenses people use to look at it.
Because it’s so simple and built on total transparency, KAOS can just keep running forever without ever losing trust. Systems that rely on control or curation often wear out that trust over time and end up needing to be replaced.
I think that separation and simplicity is the key to something that lasts. Curious what you think.
Thanks for the work you’re doing,
Brian Charlebois
kaosnow.com
(I was assisted in writing this by AI, but nothing in the KAOS website involved any AI.)