

There will soon be millions of AI agents working on our behalf for work, commerce, and democracy.
How do we ensure people’s preferences and values are faithfully represented?



The future of AI is multi-agentic
The smartest AI in the room is no longer a single brain, and the race to build AGI will not be realized in the form of a monolithic intelligence. The most interesting gains in capability are coming from systems of diverse AI agents coordinating together.
Architectures like Mixture-of-Experts (MoE) have demonstrably outperformed dense models in scaling efficiency and performance, while multi-agent platforms like AutoGen or CrewAI show how specialized agents, working as teams, can solve complex tasks in ways single models cannot. Anthropic’s own deep research agent was built on a multi-agent system, OpenAI used a multi-agent team to help achieve a gold-medal-level solution to an International Mathematical Olympiad problem, and Sakana is demonstrating how collective intelligence at inference time boosts performance.
These are some of the emerging capabilities in the shift toward multi-agentic frameworks:
Specialization: Agents can be trained or prompted for narrow competencies and composed like modules.
Parallelism: Many subtasks can be explored concurrently, then merged or adjudicated.
Deliberation Agents can red‑team each other, raising reliability and safety.
Tool and role diversity: Planners, critics, executors, and verifiers can coordinate with different tools.
Scaling: Capability improves by adding agents/experts, not just parameters in one model.
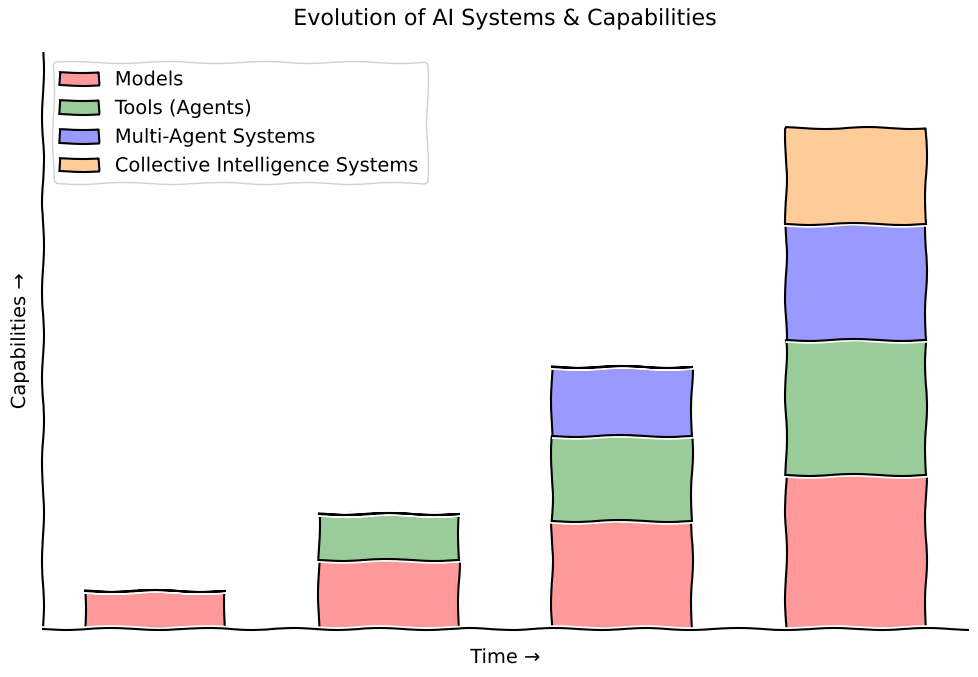
We expect increasing diversity in models and institutions over time. The AI ecosystem will likely consist of differentiated models built by a range of corporate and state actors, each with distinct capabilities, use cases, and incentive structures. In such a world, the foundational thesis of democracy, that distributed collections of intelligent beings deliver better outcomes than a single decider, is about to find its newest and most potent expression in silicon.
Advances in AI are about designing better teams. If that’s true, the bottleneck to progress becomes coordination, not intelligence. As the cost of raw intelligence approaches zero, meaningful progress requires a radical shift in focus: from the pursuit of a single, isolated intelligence to the ability to effectively orchestrate distributed intelligence.
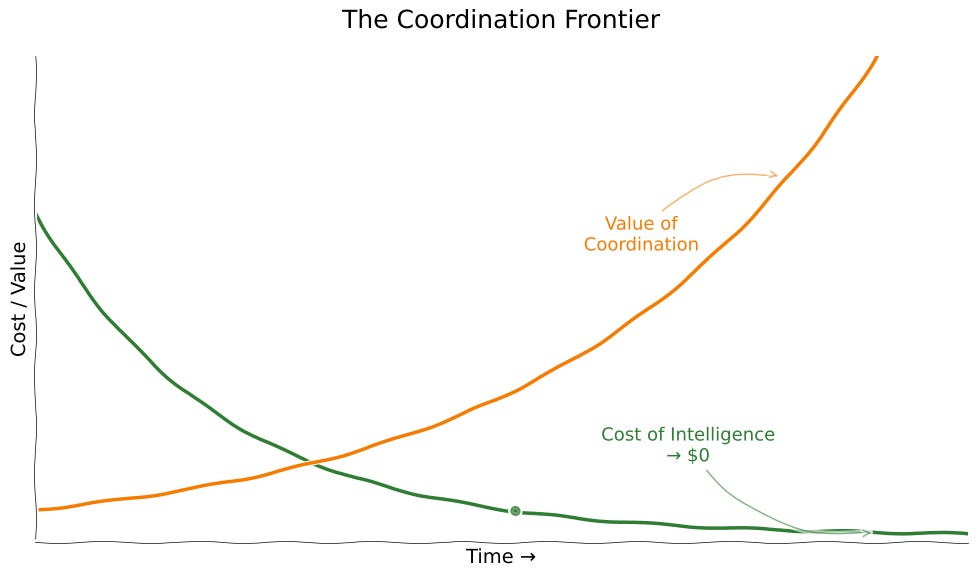
Our Old Maps Won’t Work. Collective Intelligence Is An Opportunity.
Initial teams will be built with coordination systems we already know: corporate hierarchies, single-vote democracy, market dynamics, product teams. But these systems were designed around the difficulties of delivering and translating information across systems and the limitations of human psychology: limited attention spans, slow communication, and finite energy.
AI agents don’t have these constraints. Forcing them into legible, human-centric structures may feel comfortable, but it’s suboptimal. Traditional coordination technologies were built around those limitations: hierarchies reduce cognitive load, voting systems cope with limited attention and issues of scale, markets help allocate scarce energy. These assumptions collapse when agents can act in parallel, operate continuously, and can exchange perfect information at scale.
On the technical side, new protocols must choreograph millions of agents deliberating in real time without human bottlenecks. Older technical approaches (job schedulers that process tasks in a fixed order, consensus protocols that demand strict agreement, or methods that concentrate control) were built for predictable, deterministic computing. They made sense when inputs and outputs were tightly controlled. But they fail with non‑deterministic agents that generate multiple valid paths and outcomes at once.
This ecosystem will demand entirely new collective intelligence systems built for the native capabilities of AI, and this is an opportunity to experiment and research which collective intelligence systems map best to different scenarios.
The Compounding Error Problem
As these collectives of AI agents grow from teams of ten to populations of millions, the number of potential interactions between them grows exponentially faster than the number of agents.
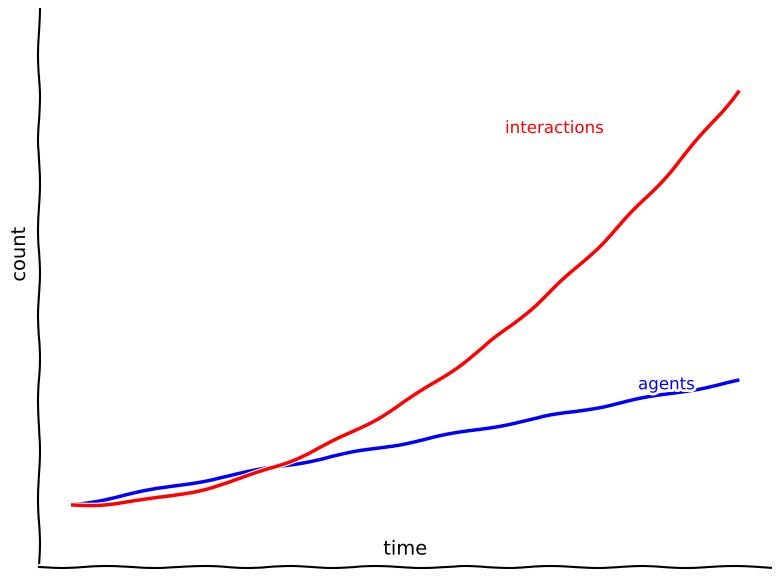
In a system defined by millions of recursive feedback loops, a tiny, seemingly insignificant error in understanding initial instructions can compound with each cycle. This makes the challenge of alignment exponentially harder than it is for a single model responding to a single prompt. What begins as a tiny divergence can snowball into systemic failure. This compounding effect makes alignment in multi-agent systems harder and more urgent.
Post-hoc user feedback isn’t enough to steer a system this complex.
The Representative Agent As An Anchor
One possible solution is to embed a high-fidelity, dynamic model of the stakeholder directly within the system. Think of it as a representative agent that acts as a persistent, real-time “judge” that works on your behalf.
This agent would be more than just a list of your preferences. Ideally, it would be a representation of your values, your goals, your desired outcomes and intentions. It functions as a persistent alignment signal — a delegate ensuring that all these agents continuously working on your behalf are acting in your best interest.
As an example, consider a sweeping piece of climate legislation, like a state mandate to phase out gas-powered vehicles, with vast but illegible trade-offs for millions of citizens. In an AI-mediated system, each citizen’s representative agent would receive a personalized forecast, calculating the mandate’s precise impact on their family finances against projected gains in local air quality and public health. For legislators, this transforms governance, moving beyond crude polls to reveal a high-resolution map of public will and the specific conditions under which a constituency would accept such a transition.
You can imagine a range of collective action problems where the current mechanisms for aggregating preferences fail to capture the true, nuanced desires of stakeholders. A representative agent, in these cases, serves as a way making those latent preferences legible both to you and to the system, often enabling more optimal, market-like, or deliberative solutions. It provides a constant alignment signal, preventing the system from drifting off course.
To work well it would need to be an adaptive, evolving model that integrates across three dimensions:
Preferences: what you like or dislike in the near term.
Goals: what you are trying to achieve in a given context.
Values: the principles you want respected in how outcomes are achieved.
Some Challenges To Consider
Building an effective representative digital agent is a different type of alignment problem, and a few problems stand out: first, accurately eliciting a person’s complex, often contradictory preferences, and second, ensuring the agent honors those preferences faithfully over time.
The core difficulty lies in the sheer dimensionality of human values. Some preferences are low-dimensional, such as a consumer purchasing an electric vehicle based on a simple trade-off between price and battery range. However, forming a coherent position on the complex climate legislation that incentivizes such a purchase is a high-dimensional problem, involving trade-offs between economic costs, environmental benefits, and social equity. In high-dimensional contexts, the probability of agent error increases significantly, as small misinterpretations of the principal’s priorities can lead the agent to deviate from their intended outcome.
Beyond accurately modeling preferences, a functional agent must also resolve the problem of delegated discretion. It requires a mechanism for determining when to act autonomously and when to revert to the human for clarification on ambiguous or high-stakes decisions. Furthermore, it must also be robust, resilient against the adversarial manipulation that may arise as these agents become central to our economic and social lives.
These challenges — eliciting high-dimensional values, ensuring robust fidelity, and knowing when to defer — are precisely why a simple preference model is not enough. They necessitate a rigorous, continuous method of verification and fidelity.
But Can You Trust Your Twin?
Of course, a representative agent is useless if it’s a poor representation of you. To know whether it is or not requires a robust Representative Agent Evaluation Framework.
To make sure that this future full of agents negotiating, bargaining and deliberating on your behalf goes well, we need to build the infrastructure that ensures these powerful systems remain extensions of human will, not replacements for it. Representative agents offer a promising path forward, but only if they can be trusted. This trust, in turn, will depend on a framework that can test and monitor their ongoing fidelity.
This framework has to do three things exceptionally well:
Measure Fidelity: It must quantify how accurately the agent represents your values and intentions.
Demonstrate Trust: It must be able to pass what we could call the Volitional Turing Test. Can it make choices so reflective of your own that you can’t distinguish its decisions from those you would have made yourself?
Probe for Gaps: It cannot be a static test. The system must actively seek out the “unknown unknowns” in its representation of you, dynamically finding and closing gaps in its fidelity.
Without this, we risk deploying systems that misrepresent populations at scale and dealing with an increasing number of principal-agent problems. This is crucial to learning how best to ensure that models can serve as reliable agents for humans.
This is where our work begins.
At the Collective Intelligence Project, we’re starting by understanding when and whether agents can be truly representative. We’re building upon two of our projects.
Global Dialogues — providing high-resolution ground truth data, from our own surveys of thousands of people across 70 countries, to evaluate how accurately a representative agent can respond to questions as if it was a certain demographic.
Weval — enabling anyone to design context-specific evaluations that test whether AI models faithfully represent their values.
The evaluation framework is designed to:
Track how effectively LLMs can predict the agreement patterns (for open-ended opinion questions) and poll choices of specific demographic segments.
Identify the conditions (e.g., data volume, question types, demographic specificity) under which LLMs are most and least accurate in these predictions.
Understand which types of questions (e.g., moral, consumer, personal, political) elicit responses that are most strongly differentiated by demographics and how well LLMs capture these nuances.
Establish a baseline for comparing different LLMs and future iterations of models.
Check if the model can adjust its predictions when given new data, rather than relying on stereotypes.
Assess the model’s ability to predict how a segment’s poll choices shift after participating in a collective deliberation.
Compare the model’s predictions with real-world survey data using clear, measurable benchmarks.
For each task, the process is consistent: the LLM is provided with a demographic profile and the relevant question text, and its quantitative prediction is then rigorously compared against the ground-truth data from our Global Dialogues dataset.
We will continue to explore novel benchmarking tools and develop the frameworks for representative agents that represent not only you, but your community. Our lessons from these experiments will inform our research into the collective intelligence systems, protocols, and tools that we will need for our multi-agentic AI future.
Great piece! Really excited about the work you’re doing at CIP.
I’m curious how you think about actionable experiments that we can run in irl settings.
Very interesting article. I’m taking a lot away from it, and it’s largely making sense. One reservation - I’m not convinced we can cross collective action problems with a strictly transactional mindset. I think a defining feature of solving collective action is that from a little “i” perspective, we need to put in more than we take out.
This is how the larger “I” grows in health and vibrancy. It also grounds us in longer view perspectives rather than individual immediacy.
So I’m not convinced even millions of agents transacting on our behalf can cross a threshold of extractive vs generative outcomes.
Curious to hear how you might think of that? I recognise the attractive proposition in market economics that promises perfect outcomes given perfect information, but I’m not sure…